Apache Kafka all what I know
“ the good driver is the one who know well how its car works ”
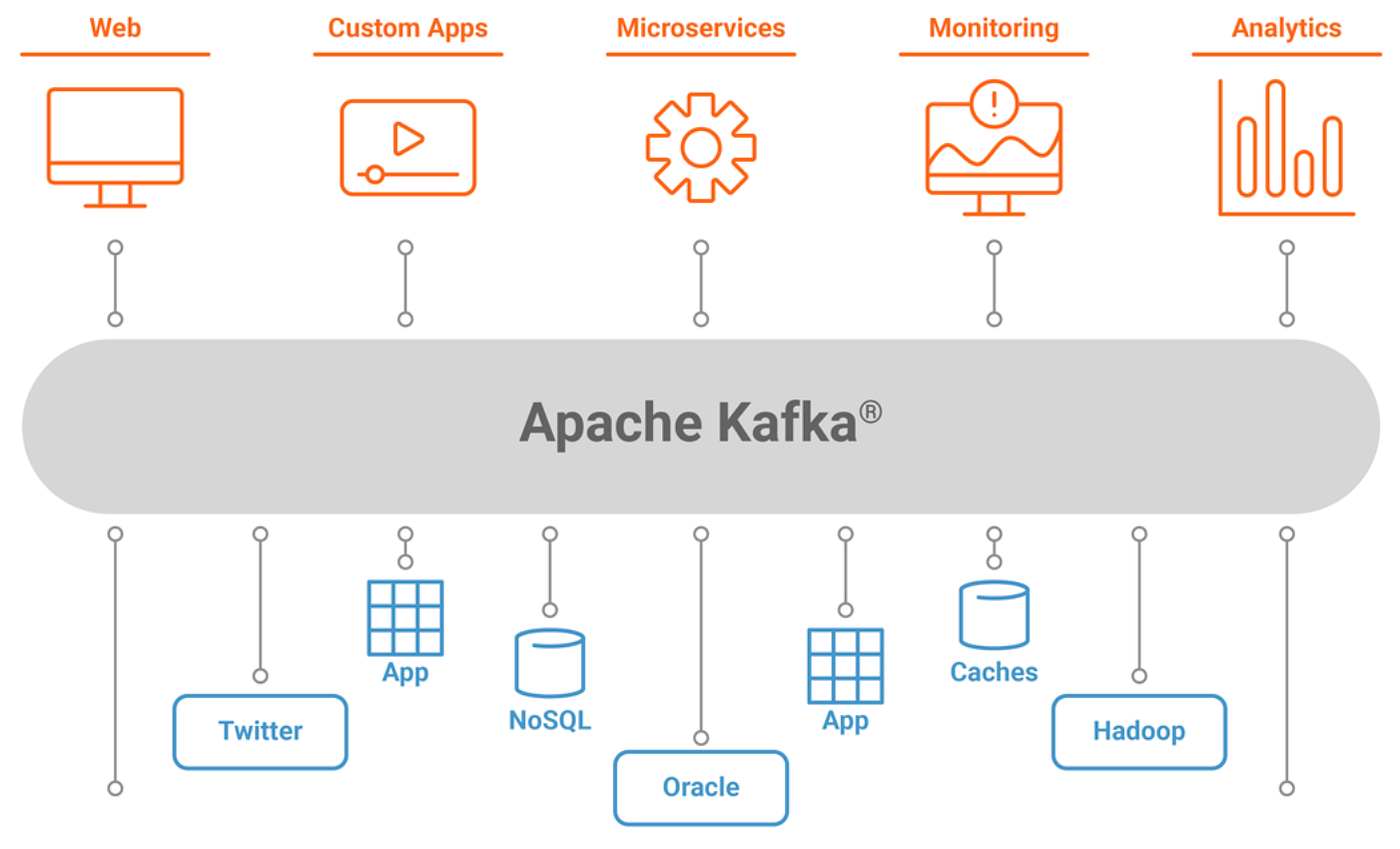
while wokring on realtime communication system across mutliple channels we need sometimes to check the best IT technologies to use so we can provide a better solution for our clients . On of the most important IT technology is apache kafka .
Defination :

“kafka is an open source distrubted streaming platform created by linkedIn . that allows for ther development of ream time event driven applications . to be more specific it allows developers to make apps that contuinuously produce and consyume streams of data records ” .
kafka is distributed its runs as a cluster “ A computer cluster is a set of computers that work together so that they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software.” , so it can span multiple servers or even multiple data centers “A data center or data centre is a building, a dedicated space within a building, or a group of buildings used to house computer systems and associated components, such as telecommunications and storage systems” . thae records that are produced are replicated and partitioned in such a way that allows for a high volume of users to use the app at the same time “ dimultaneously ” without any preceptible lag in performance and that makes kafka so fast . and also maintains a very high level of accuracy with the data records .
being distrubted gives kafka a lot of advantages that all distrubted system have Reliability “fault-tolerant”,Performance , high available and a low Latency .
Explanations :

event : “An event is a change in state . In the context of applications, events simply are things that happen within a software system. Oftentimes, they’re tied to actions that affect how a business operates or how a user navigates through a process (applying for a credit card, for example). Examples of events might include a customer logging into a service, a distribution center updating its break inventory, or a payment transaction completing. Each event should trigger one or more actions or processes in response. A common and very simple action is logging the event for monitoring purposes. However, other actions can be more complex or proactive in nature. Based on the examples above, for example, a service might respond to a specific event by serving a verification request, updating an e-commerce database, or closing an open sales ticket ”

Event Streaming : “ they are events form into event streams which reflect the changing behavior of a system this could be a continuing path of a pedestrian or an enitre sequence of products added and removed from an e-commerce cart distributing this begavior level data around a system allows us to arrive at useful conclusions just a few ms after the orignal event occured , events streams get they power from generate boundless datasets” .

event driven systems : “ it a kind of system where system compnents communicate with each others in non-direct way using events and event streams with the help of Event Bus , Event-driven architectures have three key components: event producers, event routers, and event consumers. A producer publishes an event to the router, which filters and pushes the events to consumers. Producer services and consumer services are decoupled, which allows them to be scaled, updated, and deployed independently”.


Kafka System Design :

Topic : You can have multiple topics in given application. Eg: in ecommerce application order events for order data, active products events for new active products, out of stock events for the product which are not available. So we can have 3 different queues/topics here to process given data.

Partition : As discussed earlier, incoming stream can be huge, so we split it, and store on multiple nodes. So kafka allows us to setup multiple partition for given topic so that concurrent write happens faster. And also runs replicas for each partition. There is one leader, and remaining slaves. Kafka writes incoming events to the leader partition, and other partitions sync to leader, once it gets completed, kafka send acknowledgement to the publisher. Publisher follow round robin strategy to send events to various partition by feault. You can also configure hase key based distribution, where event with given hashkey always goes to same partition. And we get events ordering at partition level, not at topic level.

Broker : Broker is a kafka server, which can have multiple partition running on it. And kafka also runs replicas of broker so that if any broker goes down, kafka still keeps running without any failure of data.

Cluster : Kafka runs multiple borkers in kafka cluster.

Consumer group : There can be multiple consumers in given consumer group. And they would be reading from multiple partitions for given topic. But all the given event gets processed by one one consumer in same consumer group whereas if we have multiple consumer groups configured for given topic, then each event gets processed by both consumer groups. This allows us to achieve many critical use cases in real time application eg: Lets say you have order streams of the products which we get from customer, now we can run two consumer group for this, the first one process these order, and the second one does analytics on order data. You need to make sure that kafka runs with multiple partitions to achieve better parallelism.



It’s important to note the relationships between broker, replica, and partition components that are highlighted, such as:
Kafka clusters can have one or more brokers.
Brokers can host multiple replicas.
Topics can have one or more partitions.
A broker can host zero or one replica per partition.
A partition has one leader replica and zero or more follower replicas.
Each replica for a partition needs to be on a separate broker.
Every partition replica needs to fit on a broker, and a partition can’t be divided over multiple brokers.
Every broker can have one or more leaders, covering different partitions and topics.


KAFKA RULES:
1-A fundamental explanation of Kafka’s inner workings goes as follows: Every topic is associated with one or more partitions, which are spread over one or more brokers. Every partition gets replicated to those one or more brokers depending on the replication factor that is set
2-fter successful leader election, if the leader for partition dies, then the partition moves to the OfflinePartition state. Offline partitions are not available for reading and writing. Restart the brokers, if needed, and check the logs for errors
3-No broker in the cluster is reporting as the active controller in the last 1 minute interval. During steady state there should be only one active controller per cluster
4-Under-replicated partitions means that one or more replicas are not available. This is usually because a broker is down. Restart the broker, and check for errors in the logs.
5-Avoid co-locating ZooKeeper in any major production environment and Do not use more than five ZooKeeper nodes without a really great reason
Why To Use Kafka :

data persistence :
kafka is diffrent than other Message Queing System cause it provides a stream history . when a consumer reads a record from kafka , this record isn’t deleted from the topic and it can be re-consumed by the same consumer or by an other consumer at a later time . and that’s make the system to recover data on failure . kafka make it easy on developers to use it is own or builtin feature to recover from failure .
Performance :
While Using Kafka we always Commenting , so we know from which index or which parition we are Going to read from and that’s make it so fast . Kafk use the Append only Commit Log every message you write it goes to a log . and the log is just append only . and this the best thing that we can do when it comes to the computre sience world . its a very Fast Operation
Kafka as Pub/Sub Under The Hood :
reactive systems refers to systems that are flexible, loosely-coupled, scalable, and highly responsive. To achieve this state, applications must exhibit elasticity, resiliency, and responsiveness through a backbone of asynchronous, non-blocking communication. This asynchronous communication helps to establish a boundary between components that ensures loose coupling, isolation, and location transparency .kafka built based on an asynchronous messaging backbone of communication . a message mean an event stream “just an item of data sent to a specific location” . in a reactive system . message driven communication centers around data being sent between the component of a specific system . Message-Driven architecture always makes systems more effecient while dealing with asynchrouns tasks and stram orientated approach so the message means data can be processed so fast .

while working with Systems that used in Event driven Architecture you need to understand deeply the observable event pattern and how its really works let’s take a small look at the observer pattern .
from wiki :
“observer pattern is a software design pattern in which an object, named the subject, maintains a list of its dependents, called observers, and notifies them automatically of any state changes, usually by calling one of their methods.
It is mainly used for implementing distributed event handling systems, in “event driven” software. In those systems, the subject is usually named a “stream of events” or “stream source of events”, while the observers are called “sinks of events”. The stream nomenclature alludes to a physical setup where the observers are physically separated and have no control over the emitted events from the subject/stream-source. This pattern then perfectly suits any process where data arrives from some input that is not available to the CPU at startup, but instead arrives “at random” (HTTP requests, GPIO data, user input from keyboard/mouse/…, distributed databases and blockchains, …). Most modern programming-languages comprise built-in “event” constructs implementing the observer-pattern components. While not mandatory, most ‘observers’ implementations would use background threads listening for subject-events and other support mechanisms provided by the kernel (Linux epoll, …).”
Keywords :

Defining keywords is the secret recipe to understand :
- Subject: It is considered as the keeper of information, of data or of business logic.
- Register/Attach: Observers register themselves to the subject because they want to be notified when there is a change.
- Event: Events act as a trigger in the subject such that all the observers are notified.
- Notify: Depending on the implementation, the subject may “push” information to the observers, or, the observers may “pull” if they need information from the subject.
- Update: Observers update their state independently from other observers however their state might change depending on the triggered event.

Lets split this design into different classes to simplify this a little bit.
- The ConcreteObservers are classes that contain information specific to the current instance. The update function is called by the subject’s
notify()operation. The observers update independently based on their current state. - The Observer is the parent class of the concrete observers. It contains a subject instance. When an observer is initialized, it registers/attaches itself to the subject.
- The Subject class has a list or a collection of observers. When an event is triggered it calls the
notify()operation which loops through all the observers by calling their update function.
KAFKA SECURITY :
There are two fronts in the war to secure a Kafka deployment:
- Kafka’s internal configuration,
- The infrastructure on which Kafka is running.
Starting with the latter, the first goal is isolating Kafka and ZooKeeper. ZooKeeper should never be exposed to the public internet (except for unusual use cases). If you are only using ZooKeeper for Kafka, then only Kafka should be able to talk to it. Restrict your firewalls / security groups accordingly. Kafka should be isolated similarly. Ideally there is some middleware or load balancing layer between any clients connecting from the public internet and Kafka itself. Your brokers should reside within a single private network and by default reject all connections from outside
. As for Kafka’s configuration, the .9 release added a number of useful features. Kafka now supports authentication between itself and clients as well as between itself and ZooKeeper. Kafka also now supports TLS, which we recommend using if you have clients connecting directly from the public internet. Be advised that using TLS will impact throughput performance. If you can’t spare the CPU cycles then you will need to find some other way to isolate and secure traffic hitting your Kafka brokers.
Thanks For reading .
